At CTI, we have identified a critical shift necessary to deliver on the promise of Data Governance (along with other essential tenets). We call the concept “Agile Data Governance” or sometimes “Governance at the point of use.” The whole point is that things change; if the world were static, governance would not be so hard.
Our approach includes these strategic tenants:
- Recognize governance at the point of use as critical for forming good data habits
- Have a rubric for classifying the variability in metadata and its relationship to data governance
- Have a clear definition of what data governance is
What follows, is an illustration to bring to life how the Agile Governance process works. Please know that while we use a diabetes management scenario to illustrate the framework, there is nothing unique to this scenario; it simply conveys concepts. So let’s go.
Suppose you work within the chronic disease improvement team of a hospital. You need to identify for all patients receiving medical services over the past 18 months those at risk of becoming diabetic, and further segment this group by different intervention programs assessing the costs of intervention versus the cost of the disease treatment and its related complications (co-morbidity). This patient list then needs to be assigned to care coordinators to act upon, and the patient progression tracked and benchmarked.
How do you even start? In most organizations, you’d need deep familiarity with the institution, the multiple data sources available, be a skilled data expert, and have a good clinical headset. This is a nigh impossibly high bar. [ similar examples are in every industry, imagine your own company for a moment.]
Now, what if our business engineer could use a search interface and get back a list of relevant data assets to explore. Better yet, what if the list included meaning definitions – e.g., patients coded FX mean “financial hardship” – along with its dependability, e.g., FX codes are not used consistently before 2017. Furthermore, what if they could click on “financial hardship” to get clarity on that definition too?
The Data Catalog repository provides this search capability while the Data Governance repository maintains the trusted meaning definitions. How the Data Catalog is set up and works is not for this blog, but conceptually it scans and indexes the variety of data sources in the organization (including the Governance repository) and infers data types: be it generic types such as currency, date, or address – or business-specific types such as financial hardship codes, medical prescription codes, or any code that can be pattern matched. In this way, the user can search “high deductible patients”, for example.
for this blog, but conceptually it scans and indexes the variety of data sources in the organization (including the Governance repository) and infers data types: be it generic types such as currency, date, or address – or business-specific types such as financial hardship codes, medical prescription codes, or any code that can be pattern matched. In this way, the user can search “high deductible patients”, for example.
Along the way, the data is also profiled and quality assessed. Profiling and quality go hand-in-hand. It arms the business user with immediate visibility into the range and frequency of values (“hey, here’s a diagnosis code P6-A that occurs infrequently and we have no idea what it means, need to sort that out”). It also arms the business user with a quality score driven off the data governance rules that have been established for the data.
How data arrives in the lake is essential, but first, let’s understand the governance and organizing structures of the lake which the arriving data occupies. Therefore, for now, we assume the lake has been populated with a variety of data as-is from its various sources, including databases, files, and analytic reports – and leave for later how the data arrived.
[ Sidebar: in general, technologists have invested energy on how to get data in with its technically interesting challenges, rather than on how to get it out, which is where the value emerges.]
In the workflow below, five different community roles collaborate in creating, enriching, securing, and governing a new patient dataset in an evolving process that dovetails with the way people naturally work.
We’ll use our earlier scenario: identify patients at risk of becoming diabetic and assess the costs of intervention versus the cost of disease treatment and its related complications (co-morbidity). This patient list then needs to be assigned to care coordinators to act upon, and the patient progression tracked and benchmarked.
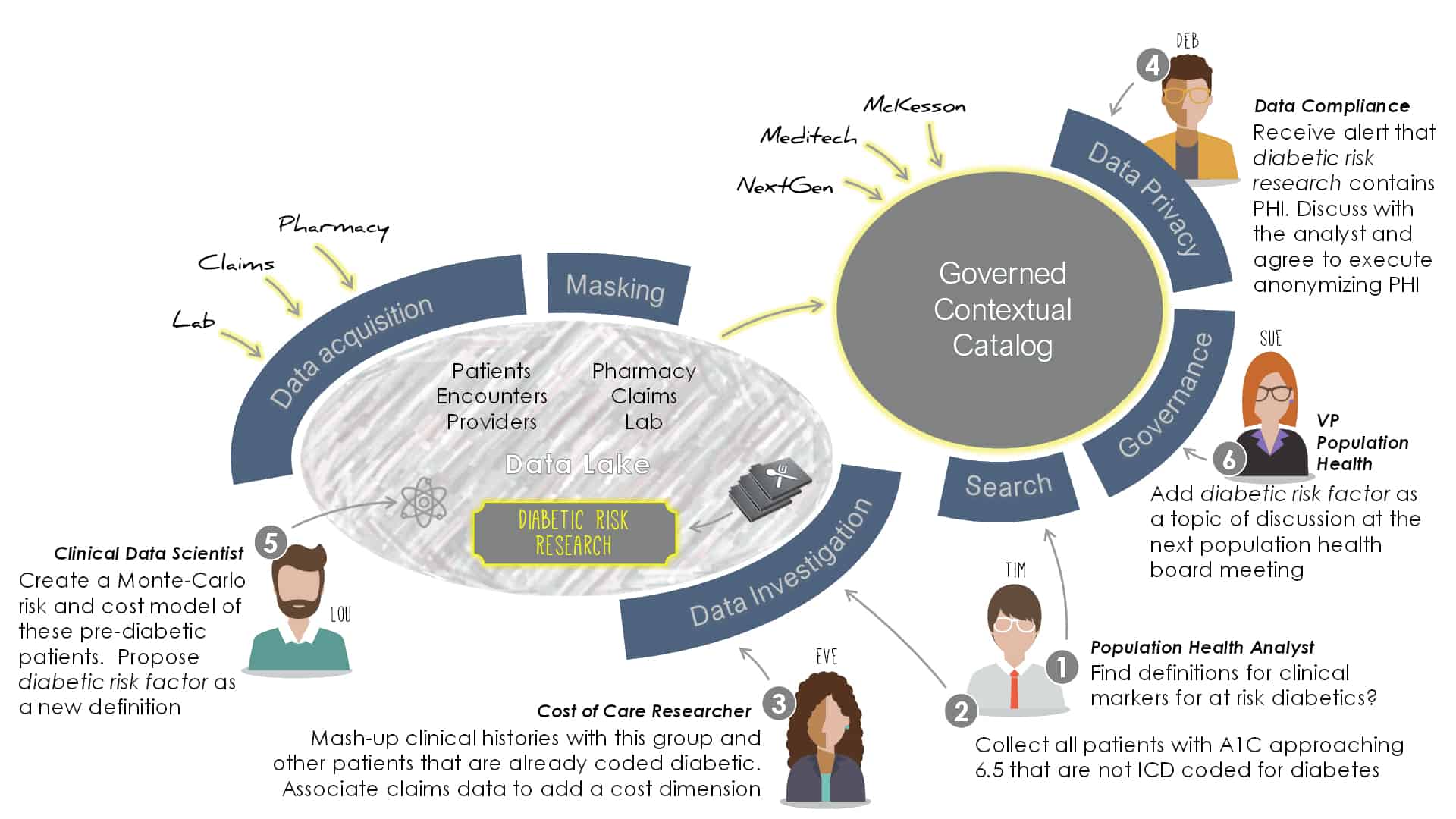
- The request lands on the desk of our Population Health Analyst, Tim. The first thing he does is search for definitions of diabetes risk. This hits the glossary stored in the Catalog. He finds a data set of diabetic patients created by another analyst but it’s not useful, he needs to find patients that are not yet diabetic but show a risk of becoming so. He also finds a definition of diabetic clinical markers that could be helpful and investigates the thresholds of these markers.
- Tim now looks for patients with a history of progression in these markers, filtering only those receiving medical services in the last 18 months (i.e. considered an active patient for insurance guidelines), and not coded for already diabetic. This becomes his starting list of, say, 1260 patients. Out of curiosity, he downloads zip-code census data from the web and blends this in to overlay socioeconomic aspects. Finally, he gives this new data set a description for future search and retrieval.
- At this point, Tim asks a colleague in the value-based programs office to help attribute costs to this list. The analyst, Eve, preps a list of patients that were coded diabetic 12-36 months ago, along with the services they have required. She blends in her own standardized services and pricing data (from Medicare) to create a normalized costing schedule rather than use the actual billing the patients have been charged.
- Meanwhile, the data compliance manager, Deb, is notified of new data containing PHI. She contacts the originator, Tim, to discuss the data and if the PHI can be masked. Tim agrees to remove key fields but needs to keep the MRN (medical reference number) since the data may be used by care coordinators in the future. Deb adds a security restriction to the dataset and makes a note in the dataset conversation.
- The population health analyst, Tim, now engages a clinical data scientist, Lou, in his department to create a risk model with varying risk scenarios that forecasts how many of the 1260 at-risk patients will become diabetic. The model incorporates some of the socio-economic factors that Tim had added earlier. The result is a risk-quotient applicable to specific demographic bands. The quotient has been back-tested as a 95% accurate predictor and asserts that of the 1260 patients, 59 will become diabetic in the next 12 months and a further 188 thereafter. Consistent with the Community Governance culture, Lou submits a new glossary term “diabetic risk factor” with a description of the algorithm, its purpose, and where it can be retrieved.
- The population health VP, Sue, is notified of the glossary submission and discusses it with Lou. She deems it so important that she decides to bring the definition to the next board meeting.
These challenges are where Operational Governance is applied. Where Data Governance is a community function that delivers trust, Operational Governance is an IT function that provides  cohesion and integrity.
cohesion and integrity.
This is a slight shift in the traditional IT data role. Typically, IT either provisions data platforms or provides ready-made data solutions (such as data warehouses and reports).
In this ecosystem, IT plays a provision-and-guardian role –IT provisions and engineers the platform components, then overlays them with robust processes and structures for the benefit of the community. This brings predictability and confidence in the data evolving within the ecosystem and assures its vitality.
I close by inviting you to download our white paper, Governed Data Lake as a Service, which explains how these processes are established, how they cooperate, and how the concept of the four types of data regions (introduced in the earlier blog) enables the digital transformation work to move from experimentation to operational.